* 본 튜토리얼은 Spark 1.3.1, HDP 2.3에서 작성되었습니다.
이번 섹션에서는 아파치 하둡 클러스터(Apache Hadoop Cluster)에 있는 데이터를 스칼라(Scala)와 아파치 스파크(Apache Spark)를 이용하여 처리하는 것에 대해 이야기 해보도록 해보겠습니다.
이 튜토리얼을 마치시면 다음과 같은 내용을 배우게 되실 것입니다.
- Spark 쉘(Shell)을 이용하여 Apache Spark 다루는 방법
- HDFS에서 텍스트 파일을 읽고 RDD 생성하는 방법
- Spark API의 풍부한 명령어를 사용하여 데이터 분석하고 다루는 방법
자 이제 SSH를 이용하여 우리 Sandbox 쉘을 띄어봅시다.
본인 컴퓨터에서 동작하는 Sandbox에 로그인 하신다면, 기본 비밀번호는 hadoop 입니다.
이제 Spark Shell을 실행시켜 봅시다.
spark-shell --master yarn-client --driver-memory 512m --executor-memory 512m
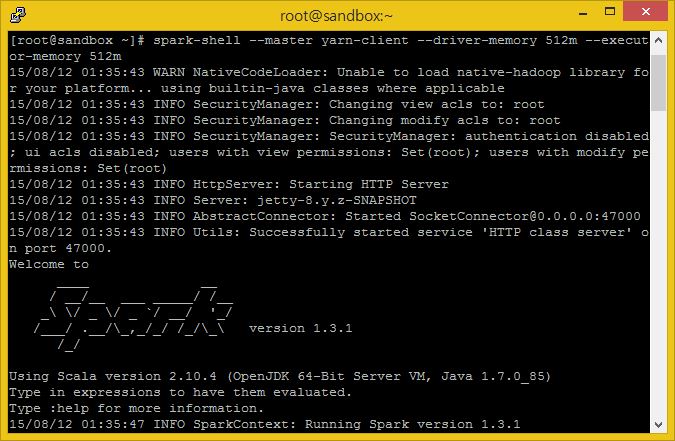
:sh 은 스파크 쉘에서 리눅스 명령들을 사용할 수 있게 해주는 명령어 입니다.
:sh sudo jps
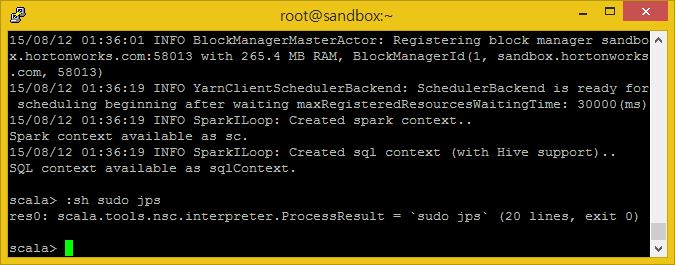
제 경우에서 보실 수 있는 res0 결과물은 ‘result #0’을 위한 출력입니다.
이제 우리가 작성한 jsp 명령라인에 대한 결과물인 result #0에 대한 결과물을 출력해봅시다.
res0.show
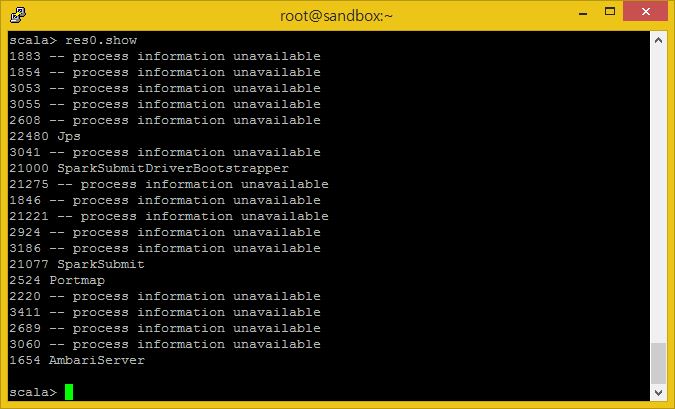
우리가 스파크 쉘을 실행하게 되면 SparkSubmit과 CoarseGrainedExecutorBackend 라는 이름의 쉘을 위한 JVM들이 다수 생성됩니다.
SparkSubmit은 ‘Spark shell’ 어플리케이션을 위해 실행되며, CoarseGrainedExecutorBackend는 우리 어플리케이션을 지원하기 위해 실행됩니다.
언제든 CTRL+D 명령으로 스파크를 쉘을 종료하실 수 있습니다.
다음으로는 littelog.csv 라는 이름의 파일을 하나 만들어서 아래 내용을 복사 붙여넣기로 Sandbox에 넣어봅시다. Sandbox HDFS의 /tmp 경로에 저장하도록 합니다.
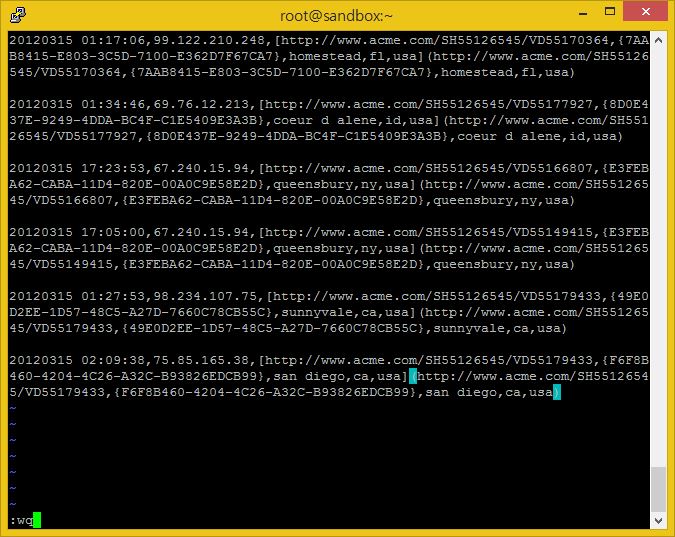
littlelog.csv 파일을 하둡 내 /tmp 경로에 넣습니다.
hadoop fs -put ./littlelog.csv /tmp/
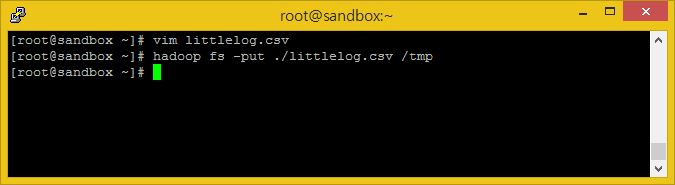
이제 데이터가 HDFS에 있습니다. Spark-shell을 켜보도록 합시다.
spark-shell --master yarn-client --driver-memory 512m --executor-memory 512m
스파크에서는 데이터 셋들이 리스트 목록으로 나타나게 되는데, 각각 다른 장치에 저장되어 있는 탓에 리스트가 많은 파티션들로 쪼개어져 있습니다. 각 파티션들은 리스트 목록에서 유일한 서브셋들을 가지고 있습니다. Spark는 Resilient Distributed Datasets(RDDs)에 저장되어 있는 데이터 셋들을 호출합니다.
littlelog.csv 파일에서 RDD를 생성해봅시다.
val file = sc.textFile("hdfs://sandbox.hortonworks.com:8020/tmp/littlelog.csv")
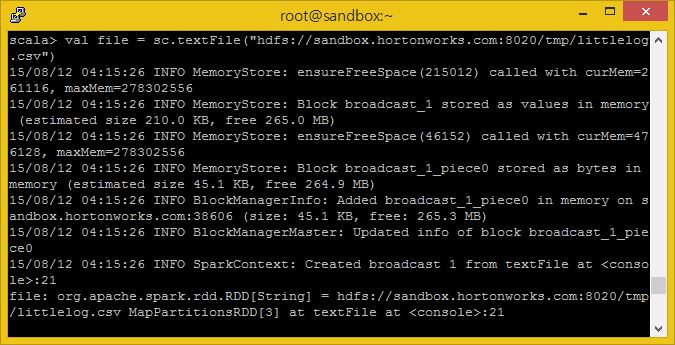
이제 RDD를 막 생성했습니다. 데이터터를 드라이버 메모리에 올리고 파일 내용을 출력하기 위해서 collect()와 같은 행동 명령을 이용해야 합니다.
file.collect().foreach(println)
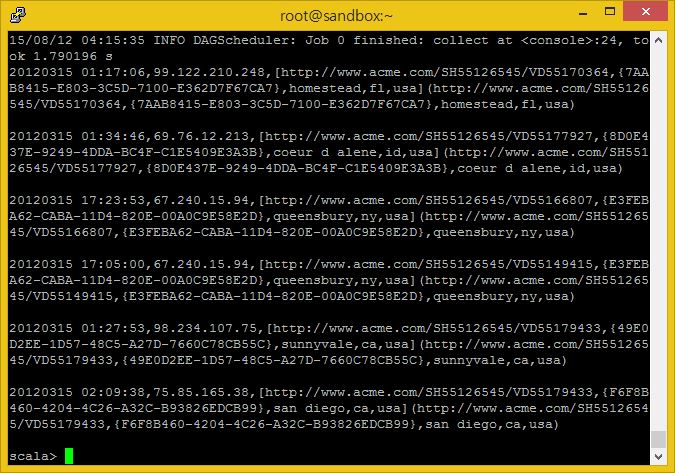
collect() 행동 명령을 아주 큰 분산 RDD에서 사용할 때에는 드라이버 프로그램이 메모리 부족과 충돌을 발생시킬 수 있습니다. 때문에 작은 dataset을 Spark로 작업하는 것이 아니라면 collect()를 사용하지 마시길 바랍니다.
RDD를 출력하는 다른 방법은 다음과 같습니다.
file.toArray.foreach(println)
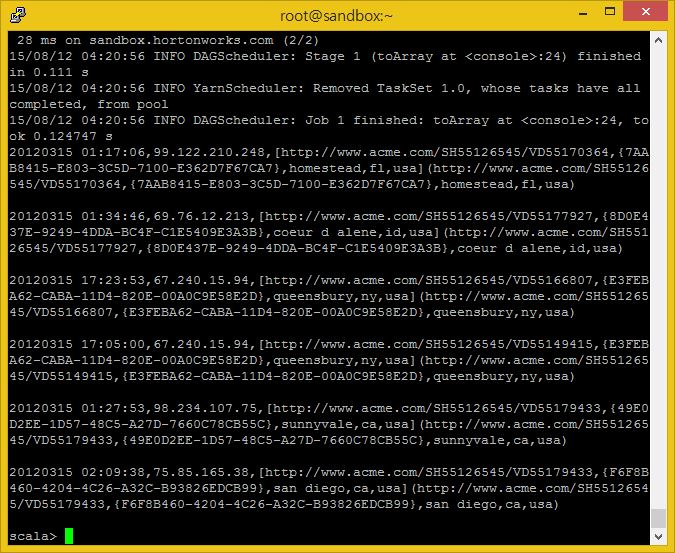
Tab을 이용해 이 RDD에 적용할 수 있는 매소드를 쉽게 찾을 수도 있습니다.
RDD이름을 바로 다음에 ‘.’ 을 치고 (지금의 경우 file. 이 되게 됩니다) <TAB>키를 눌러보세요.
그럼 이제, 이 데이터에서 몇가지 정보를 추출해보도록 하겠습니다.
상태를 키로 하고 방문자 값을 값으로 하는 맵을 생성해봅시다.
littielog.csv 파일에서 상태 정보는 각 줄의 6번째 원소(index 5)에 있으며, 맵 명령을 통해 각 줄의 정보를 파싱할 수 있도록 하는 함수에 넘겨 처리합니다. 본 함수는 6번째 원소를 파싱해 두 개의 원소를 갖는 새로운 RDD의 KEY로 사용하게 하고, 셋에서 나타나는 횟수를 세어 새로운 RDD의 두 번째 원소로 넘겨주면 이를 값으로 사용할 수 있도록 합니다.
Spark API의 map 명령을 사용해 원본 RDD에서 새로운 RDD로 변형시키거나 생성할 수 있습니다.
자, 찬찬히 한 단계씩 따라오세요. 먼저 빈 라인을 필터링 하도록 합니다.
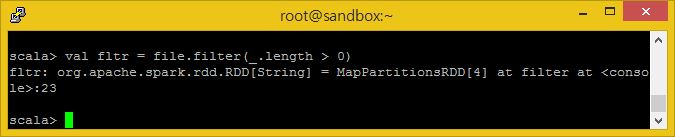
여기에서 튜토리얼을 따라 _.length > 0으로 조건을 주고 실행하였는데 이상하게 빈줄이 들어가게되어 뒷쪽에서 애러가 발생하게 되었습니다.
따라서 아래와 같이 _.length > 1 로 바꾸어 수행하였습니다.
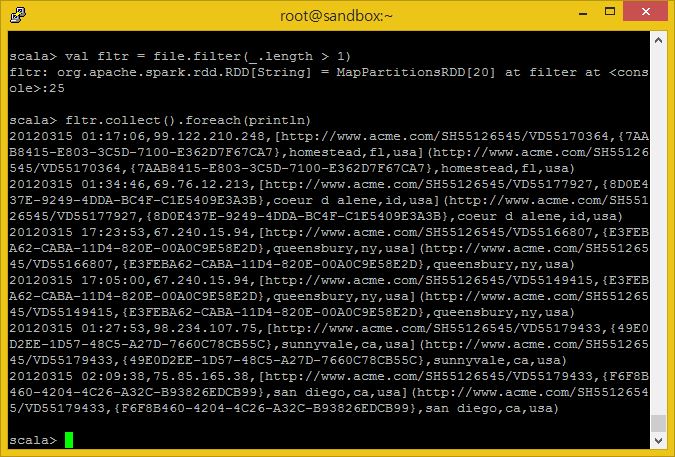
잠시만! 저기서 대체 뭐하는 거지? 라고 생각 하는 것은 스칼라에서는 본질적으로 ‘어떠한 것을 하든 나를 통해서 하라’ 라고 하는 단축입니다. 떄문에 위 코드에서 _ 는 file RDD의 각 줄이 있는 것이며, 우리는 0 이상의 길이를 가지는 줄들로 이루어진 새로운 RDD를 fltr로 부르기로 하는 것입니다.
따라서 우리는 알지 못하는 ‘무엇이든지’ 가 길이에 관한 메소드를 가지고 있어야 하며, 파일 RDD의 각 줄이 스칼라가 길이에 관한 명령을 지원하는 실제 문자열임로 인지할 것이라고 생각해야 합니다.
다른 말로 filter 메소드 괄호 안에 우리가 매개변수로 ‘무엇이든지’ 적어넣으면 로직이 적용될 것입니다.
메소드의 인수 안에서 함수를 만드는 이 패턴은 스칼라의 주된 특징 중 하나이며, 이것을 사용해서 여러분의 이해력과 프로그래밍 속도를 매우 높일 수 있을 것입니다.
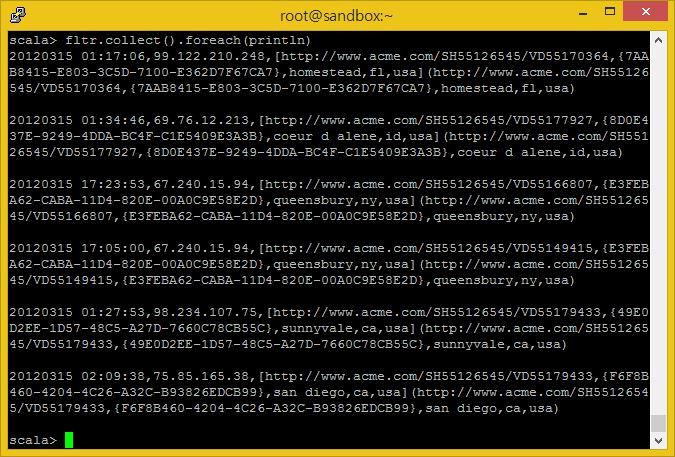
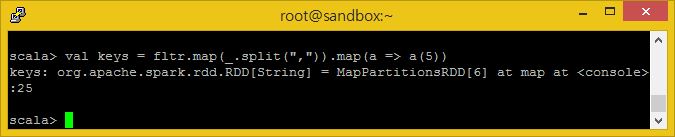
그럼, 줄을 공백으로 나누어 개별적인 컬럼으로 만들고 5번째 컬럼을 취하도록 합시다.
val keys = fltr.map(_.split(",")).map(a => a(5))
I am text block. Click edit button to change this text. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
여기서 ‘무엇이든지’ 단축을 다시 사용하고 있는 것을 알아채야 합니다. 이번에는 fltr RDD의 각 줄이 split(‘,”) 매소드를 호출하며, 결과값은 익명의 RDD에 저장되고, 그리고는 이것을 앞에는 변수 이름(타입은 추측 가능)이 뒤에는 이것에 대해 수행할 내용이 적히는 => 문법을 사용하는 함수를 정의하여 map 에 사용합니다. 이 경우에는 분할을 통해 생성된 익명의 RDD 각 줄이(an array) a 변수에 대입되며, 코드의 맨 앞줄에 정의한 최종적으로 ‘keys’라고 이름지어진 RDD에 추가될 5번째 원소를 거기서부터 추출하라고 하고 있습니다.
그럼 키 값들을 출력하도록 해봅시다.
keys.collect().foreach(println)
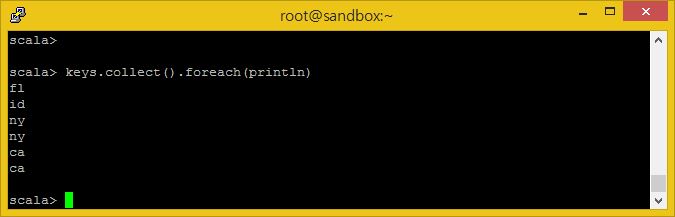
유심히 볼 것은 몇 가지 상태들은 유일한 상태가 아니라 반복되고 있는 것입니다. 여러분은 로그 기록에서 각 키(상태) 값들이 얼마나 많이 나왔는지 집계해야 합니다.
이제 각 상태를 키로 하고 이에 따른 값을 1로 하는 key-value 쌍을 만들어봅시다.
val stateCnt = keys.map(key = > (key,1))
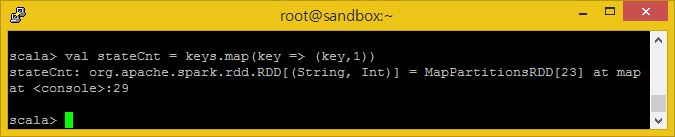
다음으로는 stateCnt RDD의 각 줄을 순회하면서, 각 내용들을 키에 따라 분리하여 숫자를 세도록 작성된 메소드에 전달하도록 합니다.
val lastMap = stateCnt.countByKey
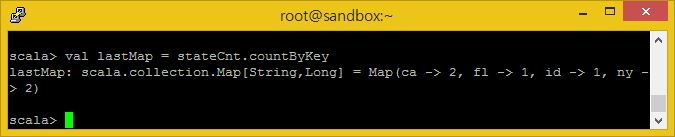
이제 결과를 출력해봅시다.
lastMap.foreach(println)
결과는 상태의 약어로 표시된 목록이며, 우리 웹 사이트를 방문한 방문자이 몇 번이나 어떠한 상태를 가졌는지 집계되어 있습니다.
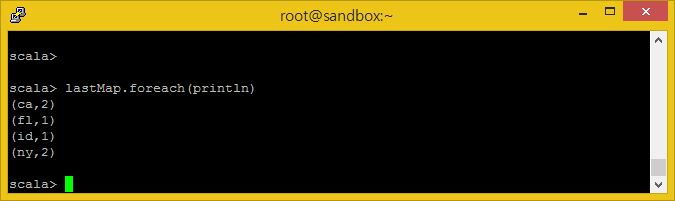
여기서 볼 것은 이시점에서도 이 세션에서 여러분이 만든 모든 RDDs 들에 여전히 접근 가능하다는 것입니다. 여러분은 여기서 어떤 과정이든지 다시 수행할 수 있으며, Keys RDD가 갖고있는 값들을 다시 출력해 볼 수도있습니다.
keys.collect().foreach(println)
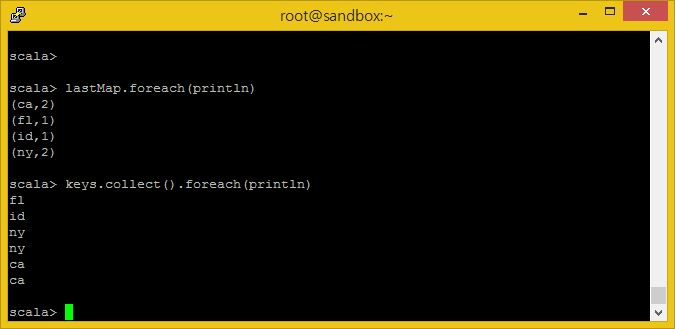
본 튜토리얼이 여러분에게 도움이 되었으면 좋겠습니다. 또한 Scala와 Apache Spark를 이용하여 HDP에 있는 데이터를 다루는 이 간단한 예제가 즐거우셨으면 좋겠습니다.
* 본 글을 위 링크 게시물을 한국어로 번역/가공한 글입니다.
![[SSL] 워드프레스에 Let’s Encrypt 적용](https://tech.sangron.com/wp-content/uploads/sites/2/2017/12/ubuntu_wallpaper_2-768x480.jpg)
![[Spark] INFO 로그 표시 끄기](https://tech.sangron.com/wp-content/uploads/sites/2/2025/01/Spark_wallpaper_1920x1080-768x480.jpg)

![[Docker] 시작하기](https://tech.sangron.com/wp-content/uploads/sites/2/2025/08/Docker_wallpaper_1920x1080-150x150.jpg)