스칼라는 JVM 위에서 동작하는 비교적 최신의 언어 입니다. 스칼라와 다른 객체지향 언어들과의 차별점은 스칼라에서는 모든 것들이 객체라는 것입니다. JAVA에 정의되어 있는 int, boolean 등의 기본 자료형들도 스칼라에서는 객체입니다. 함수 또한 스칼라에서는 객체로 다루어집니다. 따라서 객체와 같이 이들은 매개변수로 전달될 수 있고, Apache Spark에서 동작하기 위한 어플리케이션을 함수형 프로그래밍으로 작성하는 것도 가능합니다. 만약 Java나 C#으로 프로그래밍 해본 경험이 있다면, 공부를 시작한지 얼마지 않아 곧 Scala를 편하게 사용하실 수 있게 될 것입니다. 또한 커맨드라인이나 Eclipse와 같은 IDE에서 Scala 프로그램을 실행시키고 컴파일 할 수도 있습니다.
선수조건 : 해당 튜토리얼은 Spark 1.2.0으로 쓰여졌습니다. 또한 Spark 1.3.1을 사용하는 HDP 2.3에서도 동작합니다.
Sandbox를 실행하고 SSH를 통해 접속
이제 SSH를 통해 Sandbox 쉘을 열어보도록 합시다.
기본 비밀번호는 hadoop 입니다.
Spark-Shell 실행
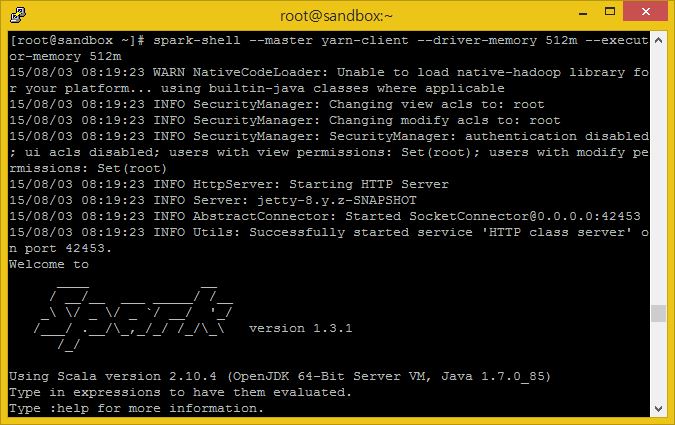
데이터를 이용해 학습을 진행하기 위해 Scala Shell을 통해 진행하는 것이 더 좋을 것 같습니다. Scala shell을 최대 수용가능 상태로 실행시켜 봅시다.
spark-shell --master yarn-client --driver-memory 512m --executor-memory 512m
Values
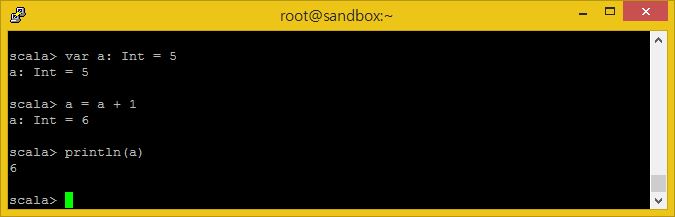
값은 가변성을 띄거나 불변하게 할 수 있습니다. 가변적인 값들은 var 키워드를 이용해 표현합니다.
var a: Int = 5 a = a + 1 println(a)
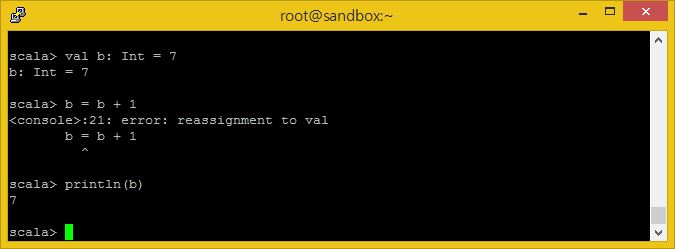
불변형 값들은 val 키워드를 이용해 표현합니다.
val b: Int = 7 b = b + 1 // Error println(b)
Type Inference
스칼라는 자바와 같이 강한 타입지정형 언어입니다. 하지만 타입 추론 면에서 괭장히 똑똑해서 프로그래머로 하여금 타입에 관한 책임을 덜어주고 있습니다.
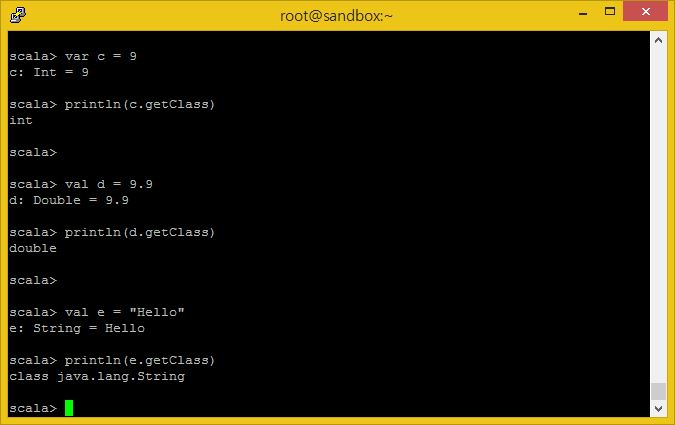
var c = 9 println(c.getClass) val d = 9.9 println(d.getClass) val e = "Hello" println(e.getClass)
Functions
함수는 def 키워드와 함꼐 정의할 수 있습니다. 스칼라에서는 함수 본체의 마지막 표현에 return 키워드 없이 값을 반환합니다.
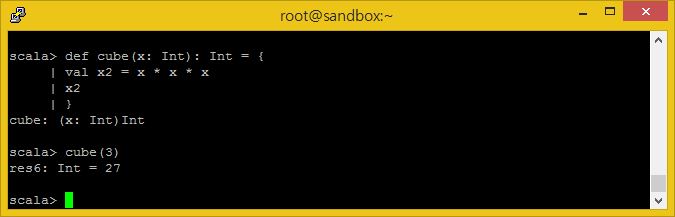
def cube(x: Int): Int = {
val x2 = x * x * x
x2
}
cube(3)
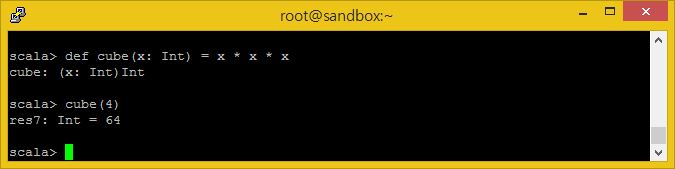
또한 중괄호들과 쉽게 추론 가능한 리턴 타입들을 날리고 함수를 더욱 간결하게 작성할 수도 있습니다.
def cube(x: Int) = x * x * x
Anonymous Functions
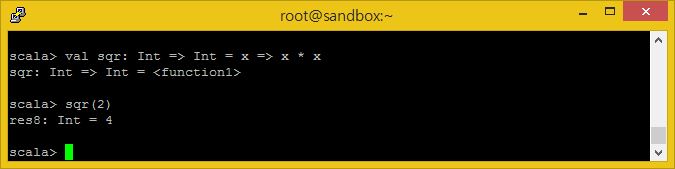
익명함수는 var 또는 val 값을 할당할 수 있습니다. 또한 함수에 전달 혹은 반환도 가능합니다.
val sqr: Int => Int = x => x * x sqr(2)
또는 익명 함수는 다음과 같이 더 짧아질 수 있습니다.
val thrice:Int => Int = _ * 3 thrice(15)
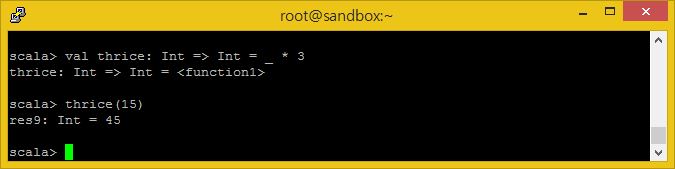
‘_’ (언더바) 기호는 입력값으로 어떠한 값이든 들어올 수 있는 속기 기호입니다.
Collections
스칼라는 Lists, Sets, Tuples, Iterators, Options 등을 포함하는 아주 편리한 컬랙션 셋을 가지고 있습니다. 만약 익명함수와 클로저를 세 개의 데이터 구조로 연결할 경우 다음과 같이 간편히 표현할 수 있습니다.
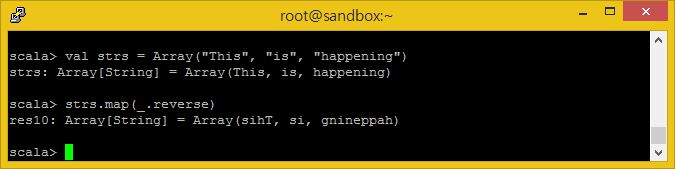
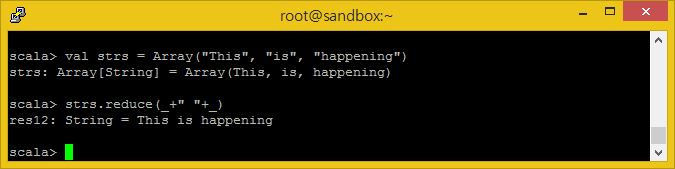
val strs = Array("This", "is", "happening")
strs.map(_.reverse)
strs.reduce(_+" "+_)
더 다양하게 학습하고 싶으시다면 http://scala-lang.org 를 방문해주세요.
* 본 글을 위 링크 게시물을 한국어로 번역/가공한 글입니다.

![[Docker] 시작하기](https://tech.sangron.com/wp-content/uploads/sites/2/2025/08/Docker_wallpaper_1920x1080-150x150.jpg)