하둡에서 Storm으로 스트리밍 데이터 처리하기
이번 프로젝트에서 우리가 이야기할 주제 입니다.
- Apache Storm 사전 설치에 대해 복습합니다.
- 처음부터 끝까지 예제를 수행합니다.
Apache Storm 이란?
Apache Storm은 분산처리 아키텍처에서 신시간 데이터 처리를 가능케하는 오픈소스 엔진입니다. Storm은 간단하고 유연합니다. 당신이 선택하는 어떠한 프로그래밍 언어와도 같이 사용될 수 있습니다.
그럼 이제 Storm 클러스터의 다양한 구성요소들에 대해 알아보도록 합시다.
- Nimbus node : 마스터 노드 입니다. (JobTracker와 유사합니다)
- Supervisor nodes : 워커의 시작/종료와 Zookeeper를 통해 Numbus들과 통신합니다.
- ZooKeeper nodes : Storm 클러스터를 관장합니다.
여기 이전에 우리가 다루었던 것들과 친숙한 용어들과 개념들이 있습니다.
- Tuples : 객체들의 정렬된 리스트입니다. 예를들면 “4-tuple”은 (7, 1, 3, 7) 일 수 있습니다.
- Streams : 제한이 없는 Tuples 배열 입니다.
- Spouts : 계산에 사용될 스트리밍 소스입니다. (예를들면 Twitter API)
- Bolts : 입력 스트리밍을 수행하고 출력 스트리밍을 만듭니다. 이것들은 아래의 일들을 할 수 있습니다
- 함수를 수행
- 필터 지정, 총계 산출, 데이터 조인
- 데이터베이스로의 알림
- Topologies : Spouts와 Bolts 네트워크를 시각적으로 표현하기 위한 전체적인 계획입니다.
사전 준비사항 :
수행 가능한 HDP 클러스터 – 손쉽게 HDP 클러스터를 구할 수 있는 방법은 HDP Sandbox를 다운로드 하는 것입니다.
설치와 설정 검증 :
Step 1:
Ambari로 로그인하여 Sandbox가 Storm을 수행할 준비가 되어있는지 체크하고, Storm 서비스 리스트를 살펴봅시다.
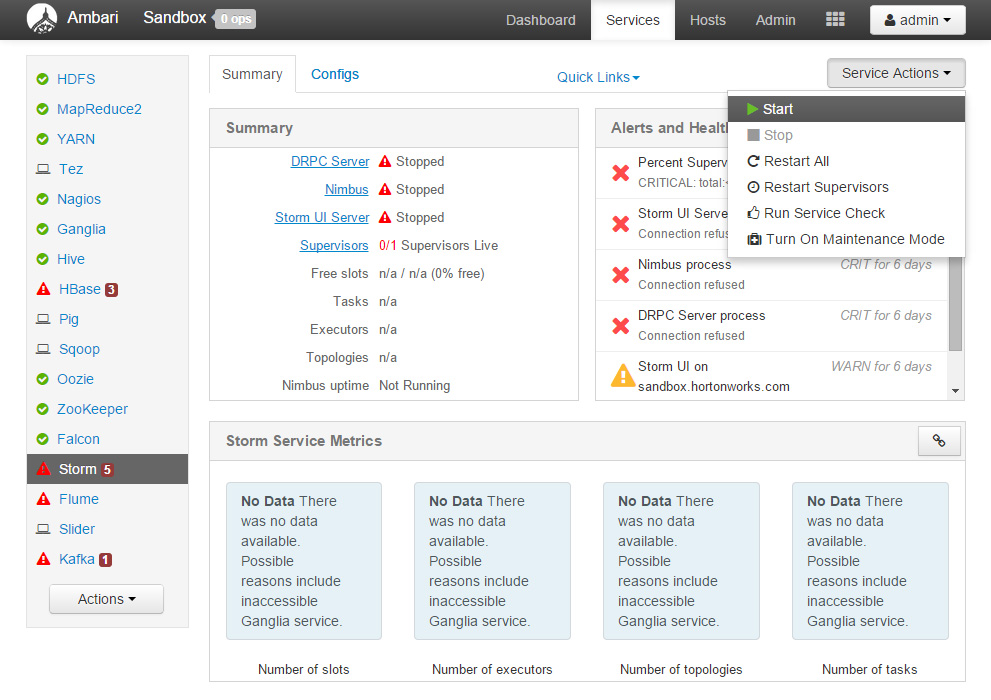
* 제가 실행했을 때 Storm이 꺼져있는 상태였습니다. Storm 서비스를 시작해야 합니다. – Rony
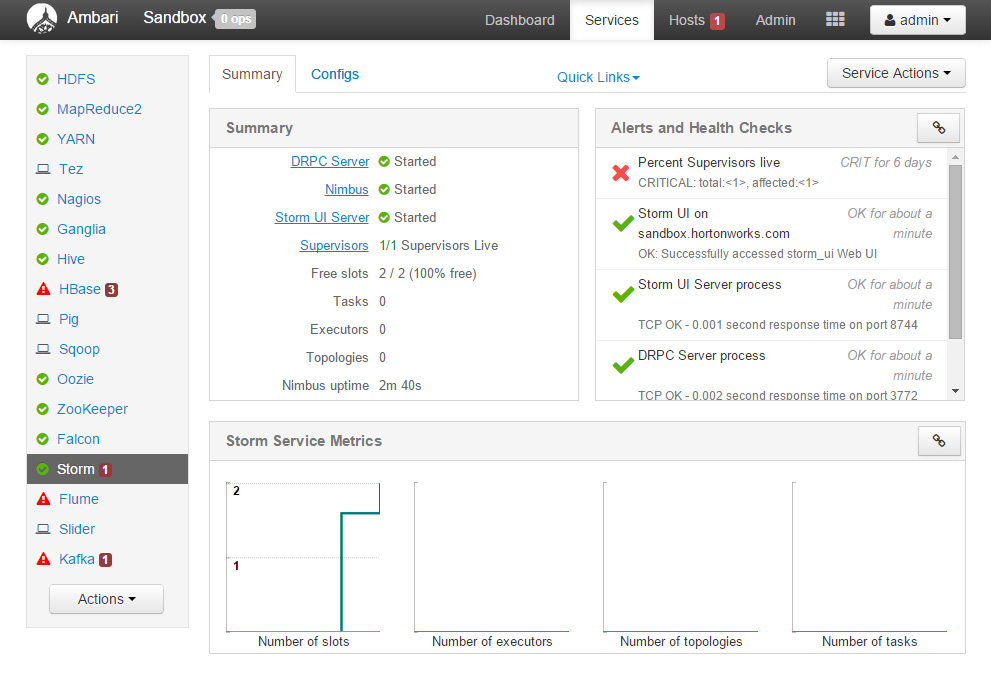
* Ambari의 기본 접속 포트는 8080 입니다. HDP Sandbox를 사용하실 경우 127.0.0.1:8080 으로 접속하시면 접속 가능합니다.
* 초기 Ambari 아이디와 비밀번호는 admin / admin 입니다.
-Rony
Step 2:
이제 Storm의 Spouts와 Bolts를 이용하여 스트리밍 사용 법을 살펴봅시다. 이것을 위해 우리는 간단한 사용법을 하나 이용할 것입니다. 하지만, 이것은 당신이 이러한 Topology를 이용하여 하둡 스트리밍 데이터를 처리하는 실제적인 경험을 제공해줄 것입니다.
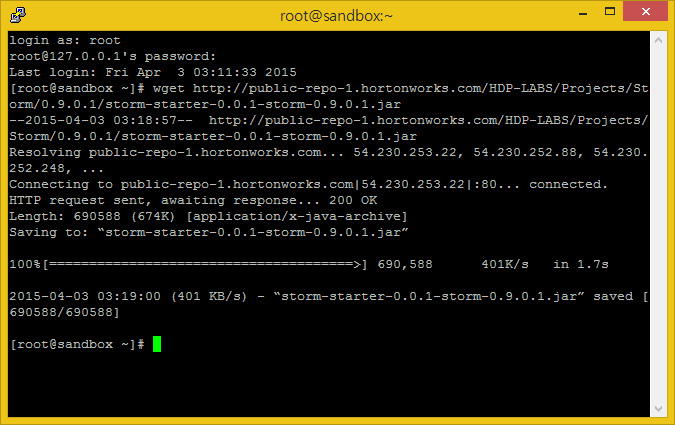
Storm Starter 킷에 있는 jar 파일을 받으세요. 이것은 다른 예제를 가지고 있지만, WordCount 연산을 수행하여 어떻게 시작하는지에 대해 살펴봅시다. 추후 Storm UI에서도 진행할 것입니다.
wget http://public-repo-1.hortonworks.com/HDP-LABS/Projects/Storm/0.9.0.1/storm-starter-0.0.1-storm-0.9.0.1.jar
Step 3:
Storm Topology 예제에서 우리는 크게 3가지 주요 처리 과정을 수행합니다.
- 문장 생성 Spout
- 문장 분할 Bolt
- WordCount Bolt
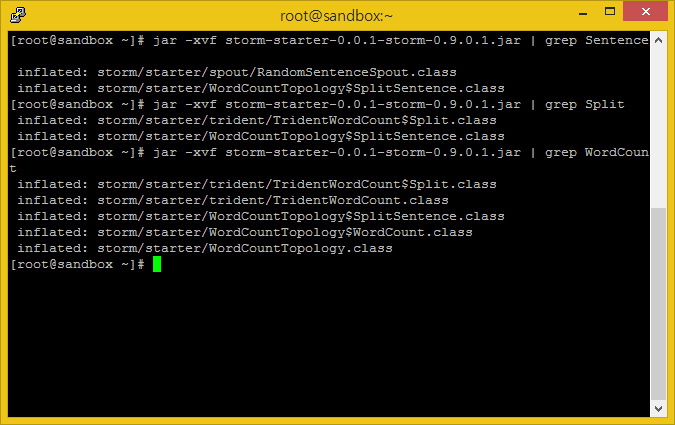
다음과 같이 하면 jar 파일 내의 클래스들을 체크할 수 있습니다.
jar -xvf storm-starter-0.0.1-storm-0.9.0.1.jar | grep Sentence jar -xvf storm-starter-0.0.1-storm-0.9.0.1.jar | grep Split jar -xvf storm-starter-0.0.1-storm-0.9.0.1.jar | grep WordCount
Step 4:
이제 Storm Job을 수행해봅시다. 여기에는 랜덤한 문장을 만들기 위해 Spout Job을 포함하고 있습니다. 분할 Bolt 처리와 Wordcount Bolt 클래스도 같이 있습니다.
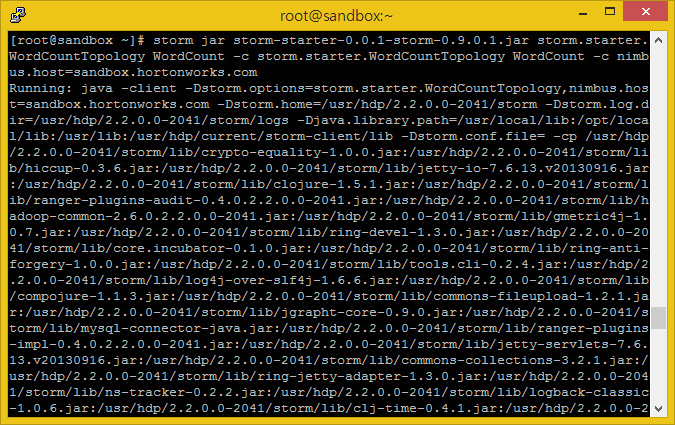
Storm Jar 파일을 실행해봅시다.
/usr/lib/storm/bin/storm jar storm-starter-0.0.1-storm-0.9.0.1.jar storm.starter.WordCountTopology WordCount -c storm.starter.WordCountTopology WordCount -c nimbus.host=sandbox.hortonworks.com
HDP 2.2 Snadbox를 사용하는 저의 경우 Storm HOME 경로가 /usr/lib/storm 폴더가 아닌, /usr/hdp/current/storm-client 입니다. 또한 Shell이 Storm HOME이 등록되어 있어 경로를 제외하고 아래와 같이 사용하였습니다. – Rony
storm jar storm-starter-0.0.1-storm-0.9.0.1.jar storm.starter.WordCountTopology WordCount -c storm.starter.WordCountTopology WordCount -c nimbus.host=sandbox.hortonworks.com
Step 5:
Storm UI를 이용해 그래픽적으로 봅시다.
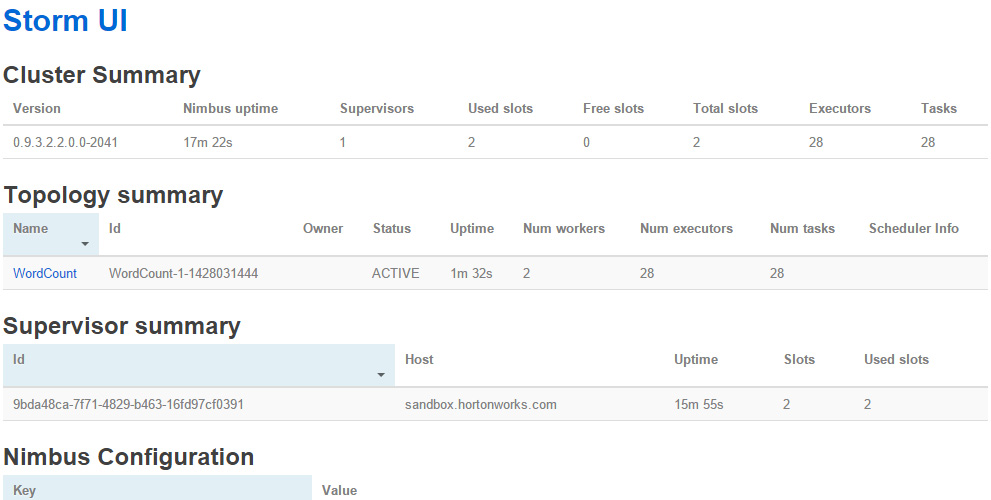
Topology Summary에서 WordCount Strom Topology를 볼 수 있어야 합니다.
Step 6:
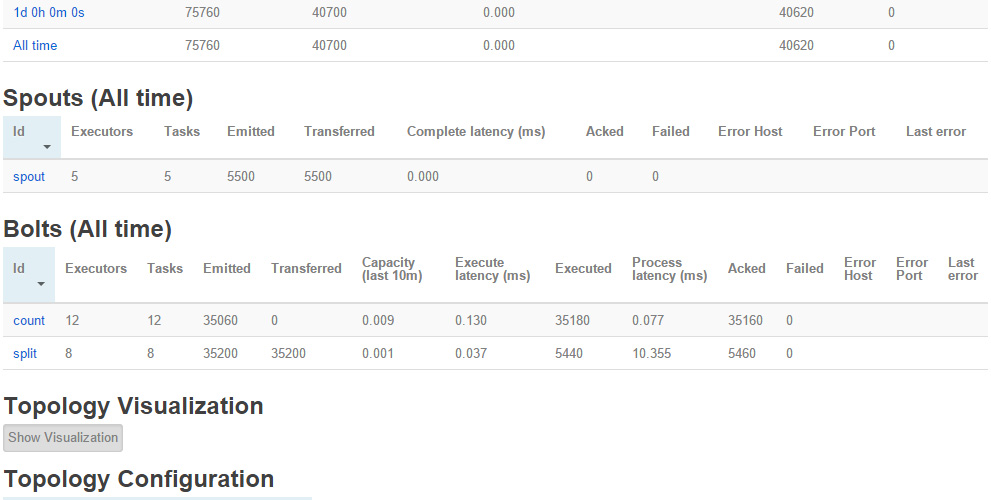
WordCount Topology를 클릭하세요. 그러면 다음과 같이 보일 것입니다.
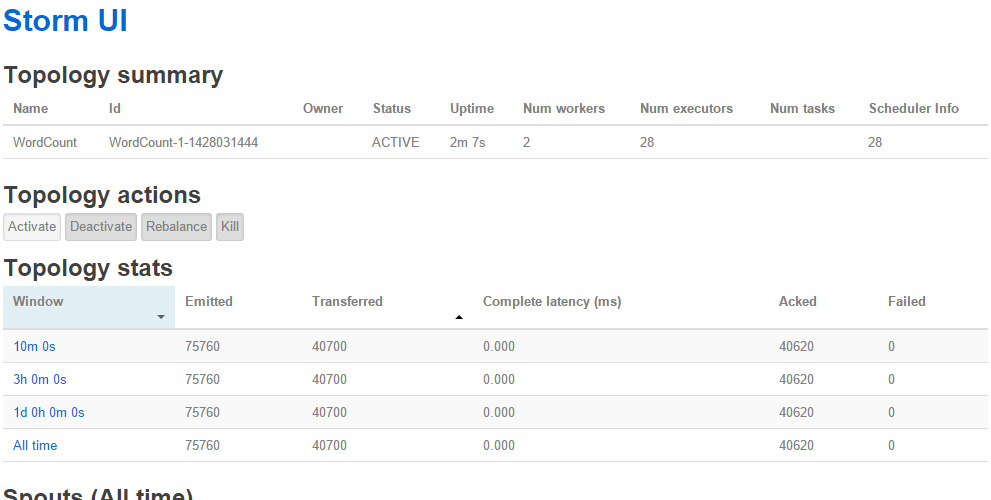
Step 7:
이 페이지에서는 Bolt 섹션에서 count를 클릭해주세요.
Step 8:
이제 실행 섹션에서 어떠한 포트를 클릭하든 결과물을 볼 수 있습니다.
Step 9:
가장 중요하게 마지막으로, 다음 폴더에서 로그 파일을 볼 수 있습니다. 이 로그파일들은 디버깅이나 상태 확인등에 매우 유용히 사용됩니다.
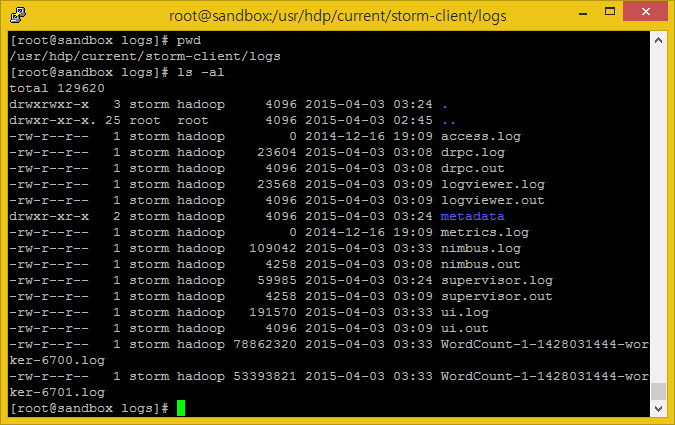
* Tutorial 에서 Storm 로그폴더 위치는 /usr/lib/storm/log 이지만 HDP 2.2 Sandbox에서의 Storm 로그파일 위치는/usr/hdp/current/storm-client/logs 입니다. – Rony
여기까지 Apache Storm을 사용해 스트리밍 데이터를 처리해보았습니다.

![[Docker] 시작하기](https://tech.sangron.com/wp-content/uploads/sites/2/2025/08/Docker_wallpaper_1920x1080-150x150.jpg)