Apache Pig 로 데이터 처리하기 [HDP Tutorial 04]
Pig 란?
Pig는 Apache Hadoop 에서 사용하는 고차원 스크립트 언어입니다. Pig는 데이터 분석 문제에서 데이터의 흐름을 설명하기에 뛰어납니다. Hadoop 에서 Pig를 사용하여 데이터를 다루는 모든 작업들을 처리할 수 있습니다. 추가적으로 Pig의 사용자 정의 함수 (User Defined Functions, UDF) 기능을 사용하여 JRuby, Jython, Java와 같은 언어를 사용할 수 있습니다. 반대로 Pig 스크립트를 다른 언어에서도 사용 가능합니다. 결론적으로 말씀드리면, 당신은 현실 세계의 비지니스 문제를 다루는 크고 복잡한 어플리케이션을 만들기 위해 Pig를 하나의 구성요소로 사용할 수 있습니다.
어떤식으로 소스로부터 데이터를 추출하고, 정해진 규칙에 따라 변형하며, 데이터 저장소에 저장하는지에 관해 설명하는 ETL 트렌젝션 모델은 Pig 어플리케이션에 대한 좋은 예시 중 하나입니다. Pig는 파일, 흐름 혹은 사용자 정의 함수(UDF)를 이용한 다른 소스로부터 데이터를 수집할 수 있습니다. 한 번 데이터를 가져오게 되면, 이를 이용하여 불러오거나, 순회하거나, 데이터들 간에 다른 변형을 가할 수 있습니다. 사용자 정의 함수(UDF)의 특징에 대해 다시 이야기하면, 데이터 변형을 위한 더 복잡한 알고리즘의 수행을 가능하게 합니다. 마지막으로 Pig는 HDFS(Hadoop Data File System)에 결과를 저장할 수 있습니다.
Pig 스크립트는 Hadoop 클러스터에서 수행할 수 있는 MapReduce job들의 모음으로 번역됩니다. 이러한 변형 과정의 한 부분으로써 Pig 인터프리터는 Hadoop에서의 실행 속도 성능 최적화를 진행합니다. 그러면 이제 앞으로 진행할 데이터 분석 작업을 위해 Pig 스크립트를 작성해볼 것입니다.
데이터 처리 작업 개요
우리는 야구 통계 자료 파일을 사용할 것입니다. 여기서 매 년 가장 많은 도루를 기록한 선수를 구해보도록 합시다. 이 파일에는 1871년부터 2011년까지의 모두 90,000 줄이 넘는 모든 통계자료가 있습니다. 여기서 가장 큰 도루 값을 찾은 경우 우리는 선수의 이름을 사용해 player id 필드를 작성하는 스크립트를 작성할 것입니다.
데이터 다운 받기
데이터 파일은 www.seanlahman.com 에 있는 자료를 사용할 것입니다. 아래에서 csv 압축파일을 다운받을 수 있습니다.
데이터를 다운 받으셨으면 해당 파일을 디렉토리 내에 압축 해제하셔야 합니다. 우리는 그 중 master.csv와 batting.csv 파일만을 사용할 것입니다.
파일올리기
상단 툴바에서 파일 탐색기(File Browser)를 선택함으로써 본 예제를 시작해봅시다. 파일 탐색기는 Hortonworks Data Platform(HDP)에 저장된 파일들을 우리가 볼 수 있게 제공합니다. 이것은 로컬 파일시스템과 분리되어 있습니다. 이것은 하둡 클러스터에서 당신이 HDFS를 볼 수 있는 화면 입니다. Hortonworks Sandbox에서 이것은 Hortonworks Sandbox VM의 파일시스템 일부분이 될 것입니다.
업로드 버튼을 클릭하고 Hortonworks Sandbox 에 올리고 싶은 파일을 선택하세요.
파일 업로드 버튼을 클릭하면 다이얼로그 창이 뜹니다. 여기서 Batting.csv 파일이 저장되어 있는 로컬 위치로 이동하고 Batting.csv 파일을 선택합니다. Master.csv 파일에 대해서도 동일한 작업을 진행합니다. 모든 작업이 완료되면 디렉토리에 두 개의 파일이 올라가 있는 것을 볼 수 있습니다.
이제 데이터 파일이 있음으로, Pig 스크립트를 작성을 시작할 수 있습니다. 화면 상단에서 Pig 아이콘을 클릭합니다.
브라우저 화면에서 Pig 사용자 인터페이스를 보겠습니다. 좌측은 저장된 스크립트 목록입니다. 우측은 우리가 스크립트를 작성할 공간입니다. 공간 아래에는 저장, 실행하기, 설명, 현재 스크립트 문법 체크 수행하기 버튼이 있습니다. 최 하단에는 로, 에러 메시지, 스크립트 결과를 볼 수 있는 상태 박스가 존재합니다.
먼저 스크립트 이름을 적는것부터 시작합시다. 첫번째 코드 라인을 작성하기 전까지는 저장이 불가합니다. 첫번째로 우리가 해야할 것은 데이터를 불러오는 것입니다. 이것을 위해 불러오기 스테이트먼트를 사용합시다. PigStorage 함수를 불러오고 데이터 구분자로써 콤마를 넘겨줍니다. 아래는 코드입니다.
batting = load 'Batting.csv' using PigStorage(',');
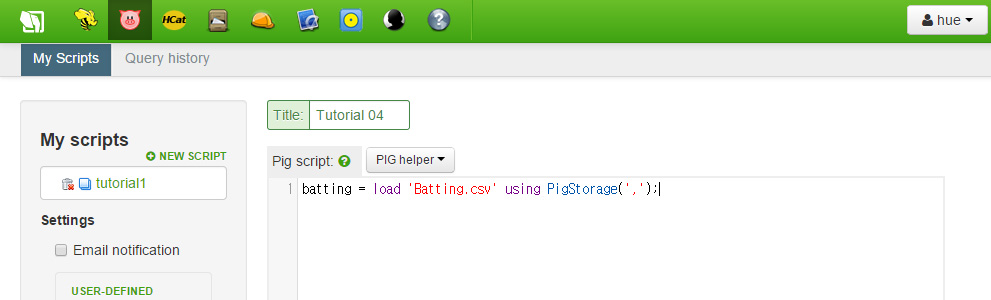
다음으로 우리가 하려고 하는 것은 필드에 이름을 붙이는 것입니다. batting 데이터 객체를 순회하기 위해 FOREACH 명령을 사용할 것입니다. 입력 공간 상단의 Pig Helper 사용하여 템플릿을 제공받을 수 있습니다. Pig Helper를 클릭한 이후, Relational Operators를 선택하고 FOREACH 템플릿을 클릭합니다. 그리고 나면 탭 키를 사용하여 각 객체를 교체할 수 있습니다.
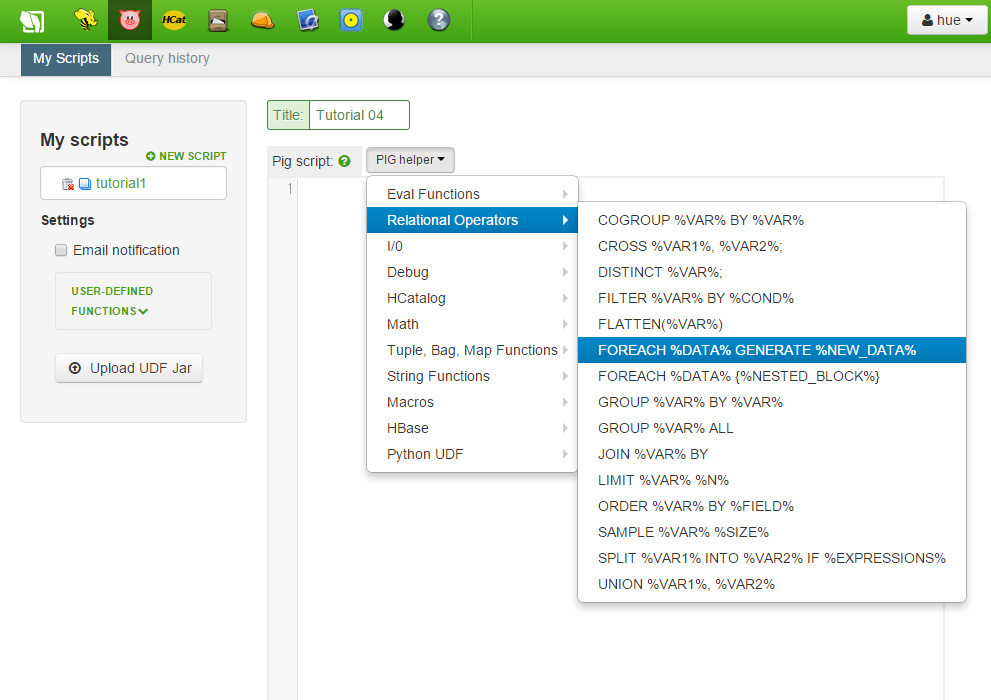
이렇게 하면, FOREACH 명령이 batting 객체들을 순회하고, GENERATE는 선택된 필드를 꺼내오며, 이것들에 이름을 할당하게 됩니다. 우리가 만든 새로운 데이터 객체에 runs 라는 이름을 붙이겠습니다. 코드는 아래와 같습니다.
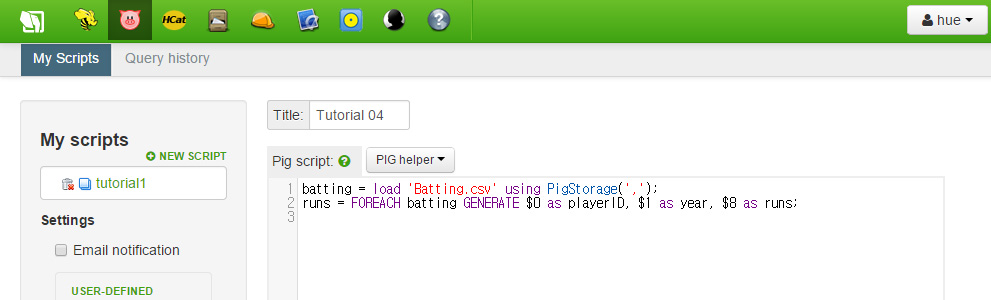
다음 줄엔 runs 내의 객체들을 year 필드로 그룹을 만들기 위한 GROUP 명령입니다. 이렇게 하면 grp_data는 year 맞추어 색인화 될 것입니다. grp_data를 year에 따라 순회할 것입니다. 다음 명령으로 다음과 같이 코드를 작성세요.
grp_data = GROUP runs by (year);
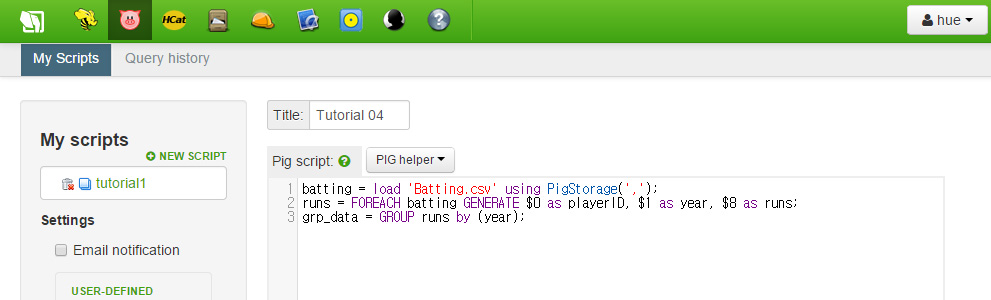
다음 FOREACH 명령으로 우리는 각 년도별 도루값 중 최대 값을 찾을 것입니다. 코드는 다음과 같습니다.
max_runs = FOREACH grp_data GENERATE group as grp, MAX(runs.runs) as max_runs;
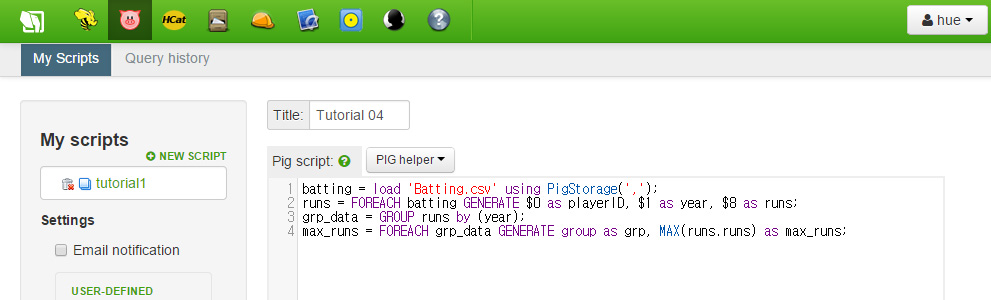
이제 우리는 최대 도루 값을 찾았습니다. 이제 player id를 얻기 위해 이것과 runs 데이터를 join 해야 합니다. 결과값은 Year, PlayerID, Run으로 구성된 데이터셋입니다. 가장 마지막에 output을 위해 데이터를 dump 합니다.
join_max_run = JOIN max_runs by ($0, max_runs), runs by (year, runs); join_data = FOREACH join_max_run GENERATE $0 as year, $2 as playerID, $1 as runs; dump join_data;
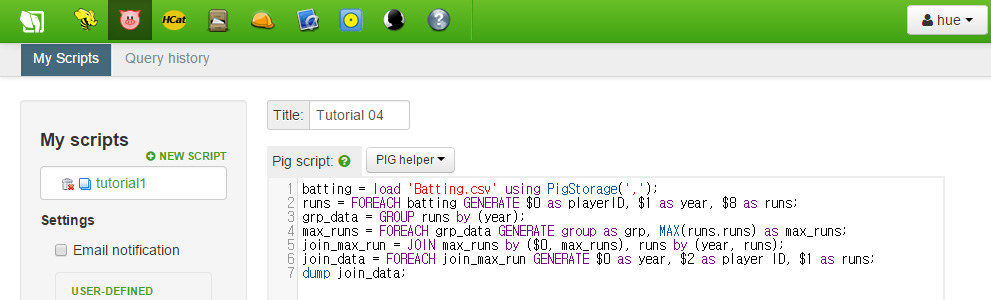
스크립트를 다시 살펴봅시다. 우선 알아두어야 할 것은 우리는 각 줄에 대한 등호 구문을 작성한 적이 없습니다. 그저 각 줄에서 우리가 하고 싶은 것들에 대해 서술했을 뿐입니다. 우리는 그저 모든 줄에 대해 적용되었을 것이라고 가정합니다. 우리는 또한 GROUP, 각 줄을 키로 정렬하고 새로운 데이터 객체를 생성하기 위한 JOIN과 같은 강력한 명령들을 사용할 수 있습니다.
이 시점에서 스크립트를 저장합시다. Title 옆에 박스에 아직 이름을 작성하지 않았다면 채워주세요. 저장 버튼을 누르고 나면 이제 당신의 스크립트가 좌측 바에서 보일 것입니다.
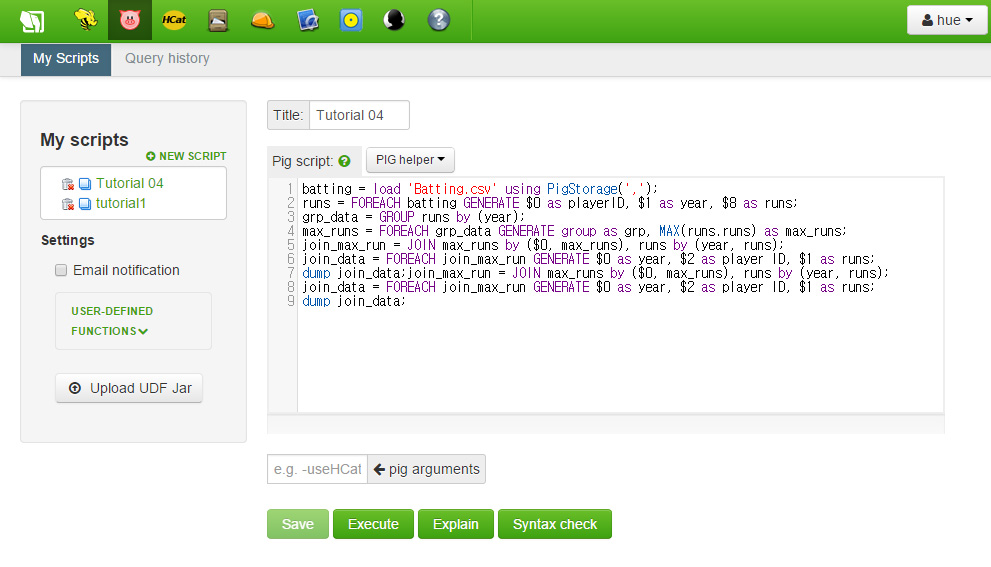
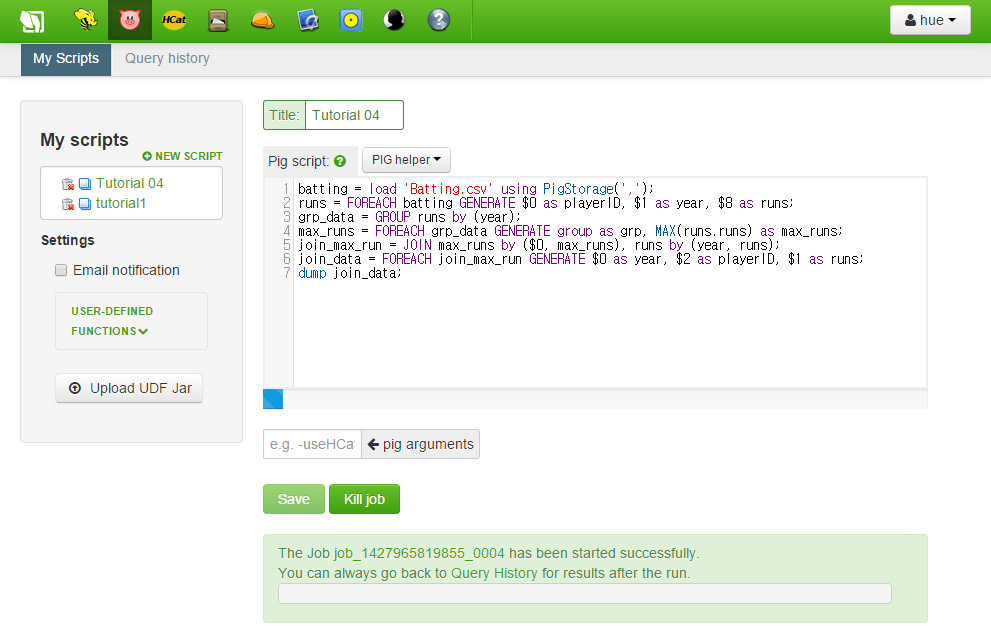
이제 입력창 하단의 실행 버튼을 눌러 우리 코드를 실행해볼 수 있습니다. job 들이 수행되기 시작하면 하단에 진행상태바가 보일 것입니다.
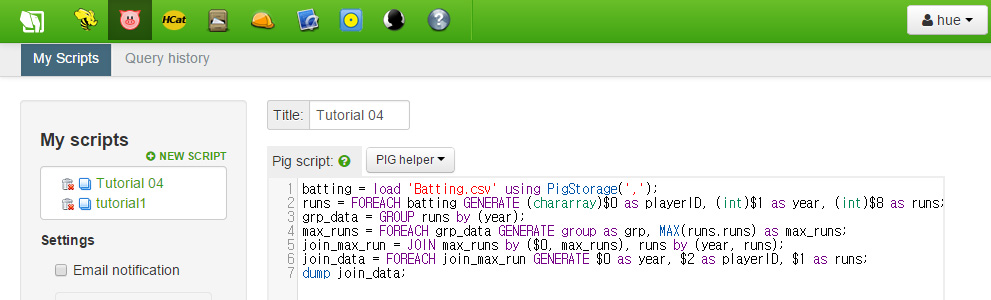
Hortonworks의 예제는 위와 같이 스크립트를 작성하게 되어 있습니다. 하지만 Hortonworks Sandbox with HDP 2.2에서 수행해보면 해당 스크립트가 작동하지 않고 실패하는 것을 볼 수 있습니다. 하단의 댓글을 참고하면 MAX 값을 정하기 위해서는 해당 자료의 자료형을 표기해주어야 합니다. 따라서 스크립트의 2번 라인이 다음과 같이 바뀌게 됩니다.
runs = FOREACH batting GENERATE (chararray)$0 as playerID, (int)$1 as year, (int)$8 as runs;
혹은
runs = FOREACH batting GENERATE $0 as (playerID:chararray), $1 as (year:int), $8 as (runs:int);
따라서 전체 스크립트는 아래와 같습니다.
batting = load 'Batting.csv' using PigStorage(',');
runs = FOREACH batting GENERATE (chararray)$0 as playerID, (int)$1 as year, (int)$8 as runs;
grp_data = GROUP runs by (year);
max_runs = FOREACH grp_data GENERATE group as grp, MAX(runs.runs) as max_runs;
join_max_run = JOIN max_runs by ($0, max_runs), runs by (year, runs);
join_data = FOREACH join_max_run GENERATE $0 as year, $2 as playerID, $1 as runs;
dump join_data;
job 이 완료되면 하단에 초록색 박스가 보이게 됩니다.
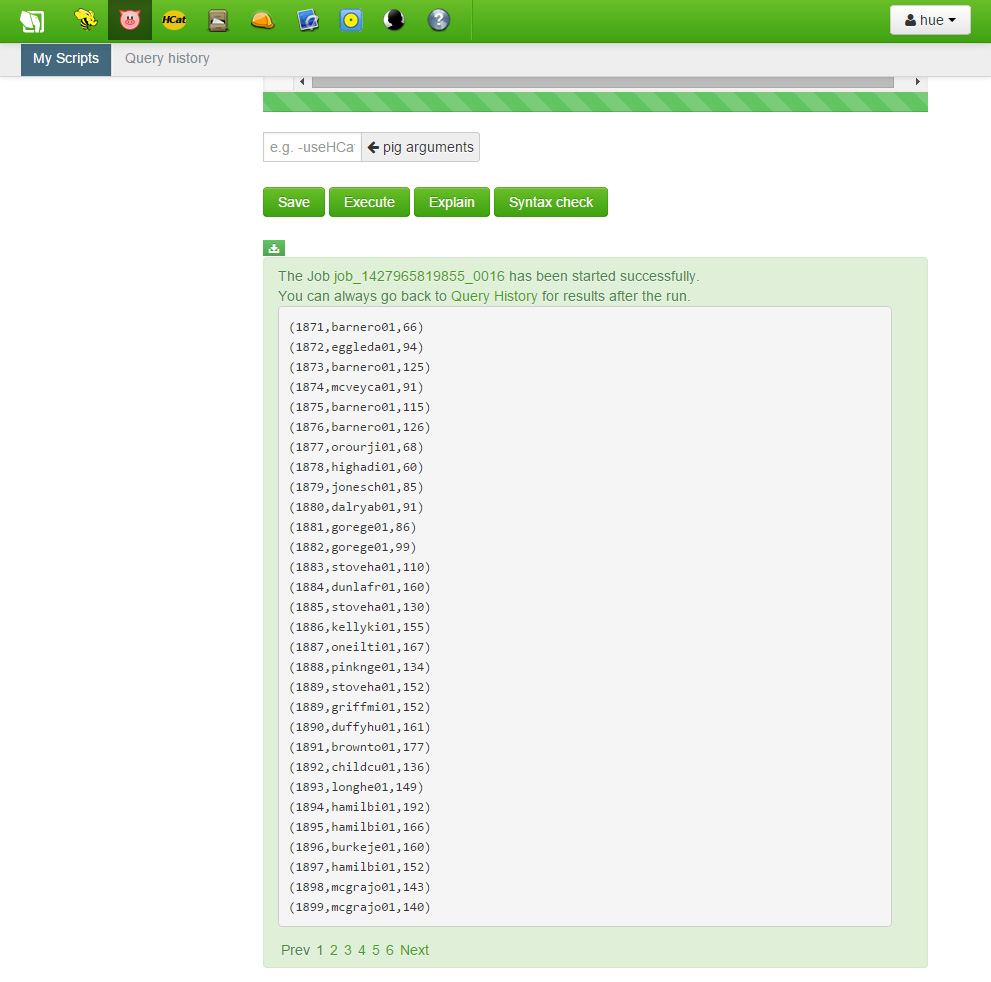
“Logs…” 글자가 있는 하단으로 스크롤을 내려 링크를 클릭하면 당신의 스크립트에 대한 로그 파일을 볼 수 있습니다.
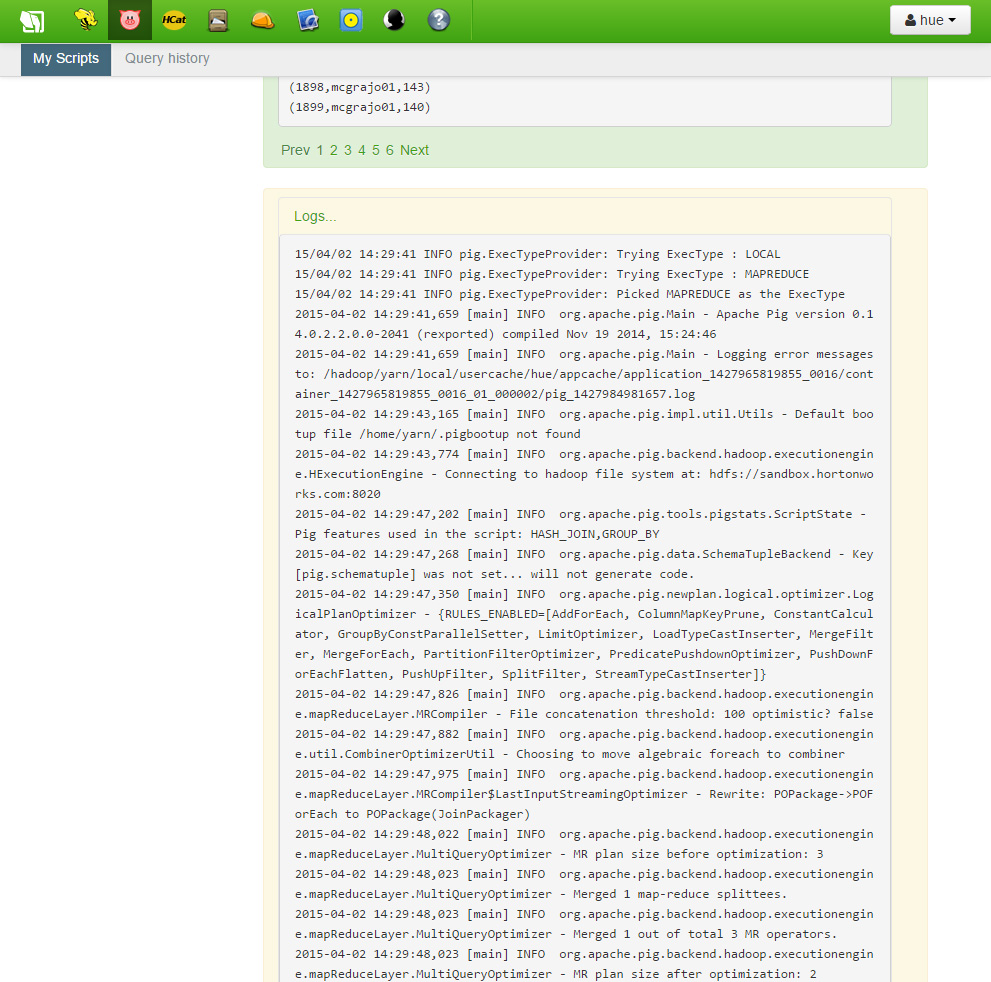
이렇게 우리는 콤마로 구분된 데이터를 읽어 처리하는 간단한 Pig 스크립트를 만들어 봤습니다. 기록 데이터 셋을 Pig로 가져온 이후 각 줄에서 playerID, year, runs을 가져왔습니다. 이후 GROUP 명령을 사용하여 이들을 year로 정렬하였습니다. 그리고 나서는 각 년도별 최고 도루 값을 찾았습니다. 마지막으로 playerID 를 연결하여 우리의 최종 데이터셋을 만들어내게 됩니다.
이전에 언급했듯, Pig 는 데이터 흐름 중에 수행됩니다. 우리는 각 그룹의 줄을 각각 고려하고, 그것들을 그룹으로써 어떤식으로 처리할지 고려해야 합니다. 더 많은 데이터 셋이나 필드들을 Pig 스크립트로 처리하는 것도 결국 이러한 흐름과 비슷할 수 밖에 없습니다. 왜냐하면 이것은 우리가 어떤식으로 데이터를 가공하기 원하는지에 집중하고 있기 때문입니다.

![[Docker] 시작하기](https://tech.sangron.com/wp-content/uploads/sites/2/2025/08/Docker_wallpaper_1920x1080-150x150.jpg)